HA 即 (high available)高可用,又被叫做双机热备,用于关键性业务。 简单理解就是,有两台机器A和B,正常是A提供服务,B待命闲置,当A宕机或服务宕掉,会切换至B机器继续提供服务。常用实现高可用的开源软件有heartbeat和keepalived,其中keepalived有负载均衡的功能。
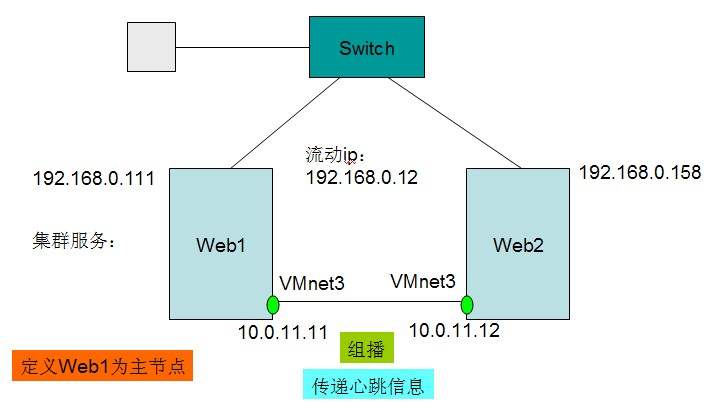
如图所示为一个 HA 结构,一个交换机下面有两台机器 web1 和 web2 ,其中 web1 为主节点,正常是它在提供服务,而 web2 备用节点是闲置的。 web1 和 web2 中间有一根心跳线,检查对方的存活状态。流动 IP ,也叫 vip 是对外提供服务的 ip ,正常情况下,是配置在 web1 上的,当 web1 宕机后, web2 会自动配置该 vip ,对外提供服务。
heartbeat 部署
下面使用 heartbeat 来做 HA 集群,并且把 nginx 服务作为 HA 对应的服务
准备工作
两台机器,都是 centos6.5,网卡 eth0 ip 地址为
|
|
eth1 ip 地址为
|
|
1. hostname 设置好,分别为 master 和 slave
主上设置 hostname
|
|
编辑文件
|
|
从上设置 hostname
|
|
编辑文件
|
|
2.关闭防火墙
主和从上都操作
|
|
主和从都关闭 selinux
|
|
3.配置 hosts
主和从都编辑
|
|
增加内容
|
|
4.安装 epel 扩展源
主和从都执行
|
|
5.安装 heartbeat
主和从都执行
|
|
6.主上(master)配置
|
|
然后编辑
|
|
更改
|
|
修改为
|
|
这是用来验证的 crc 最简单, shal 最复杂。
然后修改权限
|
|
编辑 haresources 文件
|
|
修改为
|
|
说明:master 为主节点 hostname ,192.168.0.70 为 vip ,/24 为24网段,eth0:0 为 vip 的设备名,nginx 为 heartbeat 监控的服务,也是两台机器对外提供的核心服务。
然后编辑 ha.cf
清空 ha.cf
|
|
增加内容
|
|
配置说明:
debugfile /var/log/ha-debug:该文件保存 heartbeat 的调试信息;logfile /var/log/ha-log:heartbeat 的日志文件;keepalive 2:心跳的时间间隔,默认时间单位为秒;deadtime 30:超出该时间间隔未收到对方节点的心跳,则认为对方已经死亡;warntime 10:超出该时间间隔未收到对方节点的心跳,则发出警告并记录到日志中;initdead 60:在某些系统上,系统启动或重启之后需要经过一段时间网络才能正常工作,该选项用于解决这种情况产生的时间间隔。取值至少为 deadtime 的两倍;udpport 694:设置广播通信使用的端口, 694 为默认使用的端口;ucast eth1 192.168.91.101:设置为对方机器心跳检测的网卡和 ip;auto_failback on:heartbeat 的两台机器分别为主节点和从节点。主节点在正常情况下占用资源并运行所有的服务,遇到故障时把资源交给从节点并由从节点运行服务。在该选项为 on 的情况下,一旦主节点恢复运行,则自动获取资源并取代从节点,负责不取代从节点;node: 指定主和从,各占一行,主在上从在下;respawn hacluster /usr/lib/heartbeat/ipfail:指定与 heartbeat 一同启动和关闭的进程,该进程被自动监视,遇到故障则重新启动。最常用的进程是 ipfail ,该进程用于检测和处理网络故障,需要配合 ping 语句指定的 ping node 来检测网络连接。如果系统是64,注意该文件的路径/usr/lib64/heartbeat/ipfail。
7.把主上的三个配置文件拷贝到从上
|
|
scp 命令安装
|
|
如果提示错误,主从都安装
8.从上(slave)编辑 ha.cf
|
|
ucast eth1 192.168.91.101 修改为 ucast eth1 192.168.91.100
9.启动 heartbeat
先主,后从
|
|
10.检查测试
主执行
|
|
看是否有 eth0:0

|
|
看是否有 nginx 进程

11.测试1
主上故意禁 ping
|
|
从上执行
|
|
看是否有 eth0:0

|
|
看是否有 nginx 进程

主上执行
|
|
主上恢复 eth0:0 和 nginx,从上停止 eth0:0 和 nginx 服务
12.测试2
主上停止 heartbeat 服务
|
|
从上会启动 eth0:0 和 nginx 服务
主上开启 heartbeat 服务
|
|
主上恢复 eth0:0 和 nginx 服务,从上停止 eth0:0 和 nginx 服务
13.测试脑裂
主和从上都 down 掉 eth1 网卡
|
|
主和从都会启动 eth0:0 网卡和 nginx 服务